tags:
- OS
- Deadlock
第一课 Starvation on the Dining Table
哲学家就餐问题(Dining Philosophers' Problem) 是除生产者消费者问题、读者写者问题外第三个经典的并发算法问题,由Edsger W. Dijkstra在1965年提出。哲学家就餐问题描述了这样一种情况:有五位哲学家围坐在一张圆桌旁,每位哲学家面前有一盘食物和一根筷子,哲学家们除了在思考,就是在吃饭。桌上的筷子只数是有限的,正好与哲学家数量相同。

我们先规定:哲学家需要两根筷子才能就餐,而且哲学家吃饭的时候不能打断。由于哲学家吃饭时会争夺筷子,就有可能导致一系列的问题。可能导致某个哲学家一直吃不到饭,也就是我们所说的饥饿问题,假如每个哲学家都同时拿起左手边的筷子,这时所有的哲学家永远都不能进食(所有的进程都被永久地卡住),这就是我们所说的死锁问题。
在这个人人都要挨饿的例子中,我们用哲学家类比进程,筷子则是这些进程可以重复使用的资源。要实现争端最开始的互斥,我们需要规定每次只能有一个哲学家从桌子上取筷子(即用同步机制保护资源的获取)。这样,我们就能防止出现两个哲学家同时握着一只筷子的情况了,也就是争端开始的情况。如何避免所有的哲学家挨饿是我们追求的。但之前,我们需要先了解一下死锁是什么。
第二课 Characteristics of Deadlock
Deadlock Situation
Deadlock is a set of blocked processes each holding a resource and waiting to acquire a resource held by another process in the set.
Deadlock Situation Examples
A Real Example:
- System has 2 disk drives.
- P1 and P2 each hold one disk drive and each one needs another one.
A Bridge Crossing Example:
- Traffic only in one direction.
- Each section of a bridge can be viewed as a resource.
- If a deadlock occurs, it can be resolved if one car backs up (preempt resources and rollback).
- Several cars may have to be backed up if a deadlock occurs.
- Starvation is possible.

System Model
- A system consists of a finite number of resources
- The resources are partitioned into several types, each consisting of some number of identical instance.
- physical resources: CPU cycles, memory space, I/O devices
- logical resources: files, semaphores, and monitors
In those resources, some are reusable, some are consumable.
- System model
- Resource types R1, R2, ..., Rm
- Each resource type Ri has Wi instances.
- Each process utilizes a resource as follows:
- request : may wait until it can acquire the resource
- use : use the resource for its purpose
- release : release the resource after using it
- Resource types R1, R2, ..., Rm
Necessary Conditions for Deadlock
- Mutual exclusion(互斥): only one process at a time can use a resource.
- Hold and wait(持有并等待): a process holding at least one resource is waiting to acquire additional resources held by other processes.
- No preemption(不可剥夺): a resource can be released only voluntarily by the process holding it, after that process has completed its task.
- Circular wait(循环等待): there exists a set {P0, P1, ..., P0} of waiting processes such that P0 is waiting for a resource that is held by P1, P1 is waiting for a resource that is held by P2, ..., Pn−1 is waiting for a resource that is held by Pn, and Pn is waiting for a resource that is held by P0.
The Consequences of Deadlock
- System Halt: The system may come to a complete standstill because the processes involved in the deadlock are unable to proceed.
- Resource Wastage: Resources held by the deadlocked processes remain allocated and unused, leading to inefficient resource utilization.
- Reduced Throughput: The overall system throughput decreases as processes are unable to complete their tasks.
- Increased Response Time: The response time for other processes in the system may increase due to the unavailability of resources.
- Potential Data Inconsistency: If the deadlock involves processes that are updating shared data, it can lead to data inconsistency or corruption.
第三课 Solutions to Deadlock
3.1 Four Deadlock Solutions
死锁问题可能有操作系统资源调度策略不当造成,也可能是程序员的程序不规范所造成。为了解决死锁问题,操作系统会采取不同的处理策略,可能很严格,也可能非常松弛。
3.1.1 Prevention
死锁的预防是在系统设计时就采取措施,确保系统永远不会进入死锁状态的方法。上节课中我们了解到死锁的四个必要条件。死锁预防的思路就是通过破坏死锁的四个必要条件之一就能预防死锁的发生。死锁的预防是静态的,旨在设计阶段就完全避免死锁的发生。
3.1.2 Avoidance
死锁的避免则允许系统存在某些不安全状态,但通过动态检测避免进入死锁状态。在资源分配时进行动态检查,确保每次资源分配不会把系统带入死锁状态。像银行家算法(Banker's Algorithm),它通过模拟资源分配,来判断当前请求是否安全,只有在不导致死锁的情况下才会分配资源。(带来资源损耗问题,每次资源的分配都会带来检测开销)
3.1.3 Detection and Recovery
检测和恢复死锁允许系统进入死锁状态,但通过定期检测是否存在死锁并在发现死锁后采取措施恢复系统状态。一旦检测到死锁,系统会采取措施恢复,例如终止某个进程或回收资源。这种方法适用于死锁频率较高且需要自动处理的系统。我们会使用资源分配图(Resource-allocation graph)来判断是否有死锁发生。
3.1.4 Ignore Deadlock(Ostrich Algorithm)
还有一种策略就是对死锁的无视,计算机科学中用鸵鸟算法来描述这样一种策略。鸵鸟算法的名词来源于“鸵鸟效应(ostrich effect)”,意为“将头埋在沙子里,假装没有问题”。使用鸵鸟算法的系统会假设这些问题几乎不会发生,因此不花费额外的资源去预防或检测死锁问题。至于发生死锁的原因,系统设计人员会将锅抛给程序员不当的程序。像Windows和Unix操作系统都采用这种放养式的策略处理死锁。
3.2 Deadlock Prevention
前面我们了解了死锁发生的必要条件,即当前系统中互斥、持有并等待、不可剥夺、循环等待四个条件均满足时,死锁发生。因而,我们只要让其中一个条件不满足,死锁就不可能再发生。这就是死锁预防的思路。
3.2.1 Breaking the Condition with Mutual Exclusion
互斥条件使得系统支持某些资源一时间是不能共享使用的。破坏互斥条件就是要尽量避免资源的独占使用,允许资源共享。如果两个哲学家共享一根筷子,当然也就不会存在这种餐桌上的死锁了。
但正如我们之前在 同步阶段 学到的,系统的并发性使得两个进程/线程对某些资源同时访问可能造成结果的不确定性,被称为Heisenbug。而且一些资源(打印机、CPU等)本质上就是不可共享的。所以破坏系统的互斥条件显然是不现实的。
3.2.2 Breaking the Condition with Hold and Wait
正如哲学家们需要获得一双筷子才能吃饭一样,进程也要在获得所有需要的资源之后才能开始执行。为了预防死锁,我们破坏持有并等待条件,即要求进程在开始运行之前一次性请求所有需要的资源,或者强制进程在请求资源之前释放已经占有的资源。
而进程不能预见整个运行过程中所有需要的资源,而且每次申请资源时释放已占有的资源又会导致大量的资源释放和重分配,这会使得资源的利用率、系统开销和性能降低。
3.2.2.1 Two-Phase Locking
为了避免获取锁时的持有并等待,我们可以用两阶段锁定协议的相关尝试锁定函数(Try lock)。Two-phase locking 使得哲学家拿到一只筷子后去拿另一只筷子,如果有就申请另一只筷子的资源,如果没有另一只筷子就放下原先拿到的筷子,而不是阻塞等待另一只筷子。
3.2.2.2 Try Lock Functions
pthread_mutex_trylock(): 尝试获取一个互斥锁(mutex)。如果锁不可用,立即返回一个错误代码(通常为EBUSY),而不是阻塞等待。
#include <pthread.h>
int pthread_mutex_trylock(pthread_mutex_t *mutex);
/*
Parameters:
1. mutex: A pointer to the mutex to be locked.
Return value: Returns 0 on success. If the mutex could not be acquired, returns an error code (typically EBUSY).
*/
pthread_rwlock_tryrdlock(): 尝试获取一个读写锁(rwlock)的读锁。读锁允许多个线程同时持有。如果锁不可用,立即返回一个错误代码。
int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock);
/*
Parameters:
1. rwlock: A pointer to the read-write lock to be acquired for reading.
Return value: Returns 0 on success. If the read lock could not be acquired, returns an error code (typically EBUSY).
*/
pthread_rwlock_trywrlock(): 尝试获取一个读写锁的写锁。写锁是独占的,如果锁不可用,立即返回一个错误代码。
int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock);
/*Parameters:
1. rwlock: A pointer to the read-write lock to be acquired for writing.
Return value: Returns 0 on success. If the write lock could not be acquired, returns an error code (typically EBUSY).
*/
sem_trywait(): 尝试对一个信号量(semaphore)执行P操作(等待操作)。如果信号量值为0,则立即返回一个错误代码,而不是阻塞等待。
int sem_trywait(sem_t *sem);
/*
Parameters:
1. sem: A pointer to the semaphore to be decremented.
Return value: Returns 0 on success. If the semaphore's value is 0, returns an error code (typically EAGAIN).
*/
3.2.3 Breaking the Condition with No Preemption
在哲学家吃饭时,他们手中的筷子是不可剥夺的,这就是不可剥夺的条件。如果某个哲学家边玩手机边吃饭,就可能导致其他哲学家的饥饿。我们可以设置一个管理者,当哲学家太长时间没吃饭就强制剥夺其手上的筷子。这就是不可剥夺条件的破坏。
而允许资源被强制剥夺可能引起破坏进程的正常运行。例如,强行抢占文件写入资源,可能导致数据损坏或丢失。此外,频繁的资源剥夺还会导致进程频繁地被中断和恢复,增加系统开销。
3.2.4 Breaking the Condition with Circular Wait
如果哲学家能按照一定的顺序吃饭,那么就不会发生死锁。下面是一个包含3个进程 {P1, P2, P3} 的进程集,其中P1等待P2占用的资源,P2等待P3占用的资源,P1等待P2占用的资源。

要破坏这种循环等待,我们可以采用一种全局的资源请求顺序,要求所有进程按顺序请求资源。例如,资源按某种顺序编号,进程必须按升序请求资源。
为所有的资源设定全局的顺序在复杂的系统中非常难实现,更别说操作系统中的资源需求时刻在变化的。强制进程按照顺序请求资源可能不符合实际应用的需求,降低系统的灵活性和效率。
3.3 Deadlock Avoidance
在上小节中,我们讨论了死锁的预防。其中,我们从死锁的必要条件入手讨论了四种死锁的预防方案。而现实性分析使得死锁的预防方案的实现不太现实,不仅仅是额外引入的系统开销,还会导致一系列如数据的一致性、数据损坏、系统崩溃的问题。因而我们需要考虑一种新的死锁解决方案。
3.3.1 Safe State
我们知道系统当前状态只有四个条件均满足才可能发生死锁。我们允许四种条件的存在,餐桌上也不一定刚开始就发生死锁,只是说可能进入死锁的状态。我们将系统分成两个状态:安全状态(Safe state) 和 不安全状态(Unsafe state)。安全状态不可能发生死锁,不安全状态可能导致死锁发生。
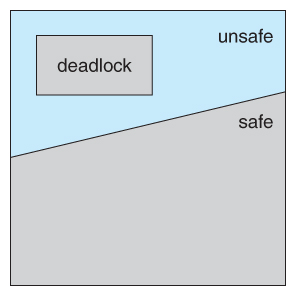
系统在运转过程中,难免进入不安全状态。在死锁的预防中,我们预防系统进入不安全状态。但在死锁的避免中,我们准许系统进入不安全状态,但是通过动态检测资源分配状态来确保系统不会进入循环等待状态。
3.3.2 Safe Sequence
3.3.2.1 Ordering of Resources
资源申请的顺序对于死锁的影响是巨大的,在同步的阶段中,我们也感受过类似的事情。假如我们有两种资源R1和R2,它们的数量都为1,如下两个进程并发执行时并不处在安全状态。因为进程A可能持有R1而进程B持有R2,两个进程都进入阻塞态等待另一资源。环状依赖出现,系统发生死锁。
Process A
1. wait(R1)
2. wait(R2)
3. Statement
4. signal(R1)
5. signal(R2)
Process B
1. wait(R2)
2. wait(R1)
3. Statement
4. signal(R1)
5. signal(R2)
如果我们调整资源的申请顺序,进程B的资源申请顺序与进程A一致,这时系统将不存在持有并等待的条件,死锁避免。当进程数量很多时,这种调整进程资源的申请顺序的方案将变得臃肿复杂。
Process B (The second try)
1. wait(R1)
2. wait(R2)
3. Statement
4. signal(R1)
5. signal(R2)
为了避免持有并等待并减少进程间的资源竞争,我们集中式分配所有资源给一个进程,减少死锁的可能性。
3.3.2.2 Being Safe
在上面的例子中,如果我们不调整资源的申请顺序,系统就会处于不安全状态。为了避免死锁发生,我们可以集中式地为某一个进程分配资源,并引入系统的安全性检查机制,确保资源的分配不会导致系统进入不安全状态。这就是死锁避免的基本思路。
为了实现这一点,系统在每次资源请求时需要进行安全性检查。假设某个进程请求资源,系统会模拟这个分配过程并检查是否会导致死锁。只有在确认不会进入不安全状态的情况下,系统才会实际分配资源给该进程。
例如,我们可以让线程A先获取R1,再获取R2,而线程B则在确保线程A释放资源后再请求资源。通过这种方式,系统可以确保所有进程都在一个安全的状态下运行,避免死锁。
3.3.2.3 Safe Sequence
当一个进程申请可用资源时,系统需要确认资源的分配会不会使系统处于安全状态(Safe state)。如果系统能够找到一个进程执行顺序,使得每个进程在其所需资源都可以满足的情况下运行并最终释放资源,从而使得其他进程也能继续运行并完成,那么这个顺序就是安全序列(safe sequence)。
- 如果系统处于安全状态,则存在至少一个安全序列。
- 如果系统处于不安全状态,则不能保证一定存在一个安全序列。
3.3.3 Banker's Algorithm
银行家算法是由 Edsger W. Dijkstra 提出的一种用于死锁避免的算法。它通过模拟资源分配过程确保系统始终处于安全状态,从而避免死锁的发生。银行家算法的基本思路为:1)资源请求;2)安全性检查;3)系统分配资源。
当某个进程请求资源时,系统并不会立即分配资源,而是会先子类当前的资源分配状态,然后模拟给各个进程资源分配的过程。经过模拟,系统会检查是否存在一个安全序列。只有在找到安全序列的情况下,系统才会对资源进行有顺序的分配。如果安全性检查不通过,即不存在安全序列,系统则会拒绝资源请求。
3.3.3.1 Find the Safe Sequence
假如我们有以下系统,请问是否存在安全序列呢?
| Process | Allocation | Maximum | Available | Need |
|---|---|---|---|---|
| A, B, C | A, B, C | A, B, C | A, B, C | |
| P0 | 0, 1, 0 | 7, 5, 3 | 3, 3, 2 | 7, 4, 3 |
| P1 | 2, 0, 0 | 3, 2, 2 | 1, 2, 2 | |
| P2 | 3, 0, 2 | 7, 0, 2 | 4, 0, 0 | |
| P3 | 2, 1, 0 | 2, 2, 2 | 0, 1, 2 |
我们一步一步来分析:
- 当前可用资源为 {3, 3, 2},资源可以分配给P1和P3;(我们用P1做例子)
- P1完成后释放资源,我们接着更新Available为 {5, 3, 2};
- 之后资源能够分配给P2和P3,我们这里选择P2进行分配;
- P2完成后释放资源,我们更新Available为 {8, 3, 2};
- 然后P3的资源请求能够得到满足,我们将资源分配给P3;
- P3完成后释放资源,现在Available为 {10, 4, 4};
- 最后,系统资源能够满足P0的资源需求了,我们将资源分配给P0。P0执行结束后释放资源。
经过这7步的分析,我们得到了 P1->P2->P3->P0 的安全序列。实际上还有安全序列。但是我们只需要一条就好了。
3.3.3.2 Algo Implementation
#include <stdio.h>
int main() {
int numProcesses = 5; // Number of processes
int numResources = 3; // Number of resources
int allocationMatrix[5][3] = {{0, 1, 0}, {2, 0, 0}, {3, 0, 2}, {2, 1, 1}, {0, 0, 2}}; // Allocation Matrix
int maxMatrix[5][3] = {{7, 5, 3}, {3, 2, 2}, {9, 0, 2}, {2, 2, 2}, {4, 3, 3}}; // MAX Matrix
int availableResources[3] = {3, 3, 2}; // Available Resources
int isFinished[numProcesses], safeSequence[numProcesses], index = 0;
for (int k = 0; k < numProcesses; k++) {
isFinished[k] = 0;
}
int needMatrix[numProcesses][numResources];
for (int i = 0; i < numProcesses; i++) {
for (int j = 0; j < numResources; j++)
needMatrix[i][j] = maxMatrix[i][j] - allocationMatrix[i][j];
}
for (int k = 0; k < numProcesses; k++) {
for (int i = 0; i < numProcesses; i++) {
if (isFinished[i] == 0) {
int flag = 0;
for (int j = 0; j < numResources; j++) {
if (needMatrix[i][j] > availableResources[j]) {
flag = 1;
break;
}
}
if (flag == 0) {
safeSequence[index++] = i;
for (int y = 0; y < numResources; y++)
availableResources[y] += allocationMatrix[i][y];
isFinished[i] = 1;
}
}
}
}
int flag = 1;
for (int i = 0; i < numProcesses; i++) {
if (isFinished[i] == 0) {
flag = 0;
printf("The system is not safe.\n");
break;
}
}
if (flag == 1) {
printf("SAFE Sequence: ");
for (int i = 0; i < numProcesses - 1; i++)
printf("P%d -> ", safeSequence[i]);
printf("P%d\n", safeSequence[numProcesses - 1]);
}
return 0;
}
3.3.3.3 Prevention vs. Avoidance
与死锁的预防相比,死锁的避免实现起来好像更切合实际了,但是这一切都是有代价的。首先就是死锁避免的算法实现起来过于复杂。我们举了一个非常简单的例子,但实际上系统不可能仅仅只有这几个进程在争夺资源。甚至在安全性检查时如果有高优先级进程插队也是我们要考虑的问题。
如果进程频繁的进行资源请求,系统就需要进行频繁的安全性检查,引入了额外的开销。再者,系统需要提前知道每个进程现在和未来的最大资源需求,对于资源需求固定且可预测的系统,死锁避免的算法尚且可行。但不太适用于动态变化的系统。
为了尽可能地避免死锁的发生,算法在一些情况下可能会趋于保守,拒绝一些可安全分配的资源请求,从而降低系统的并发性和效率。由于种种制约,银行家算法在死锁的避免上发挥的作用极其有限,然而,银行家算法在死锁的检测上可以大放异彩。
3.4 Deadlock Detection and Recovery
3.4.1 Less Efforts
我们回到餐桌上,我们先用一个形象的例子来类比一下死锁的避免。我们把操作系统类比为一个管家,负责筷子的分发。对于死锁的避免,管家在每次分配筷子时都需要思考按什么样的顺序来分配筷子,这时需要时间的,多一份思考就意味着哲学家吃饭的时间少一分。这是我们不愿看到的。
对于死锁的检测和恢复,管家分发筷子时不需要考虑会不会引起死锁问题。只需要在发生死锁时介入(死锁检测),打破死锁的局面即可(死锁恢复)。使得管家可以用更多的时间在其他更重要的事情上。
为了提高系统的效率,我们需要另外一种解决死锁的方法。而且实际上,系统发生死锁的概率并不大,我们是否可以允许系统进入死锁状态,并通过死锁的检测与恢复让系统解除死锁状态呢?
3.4.2 Resource Allocation Graph
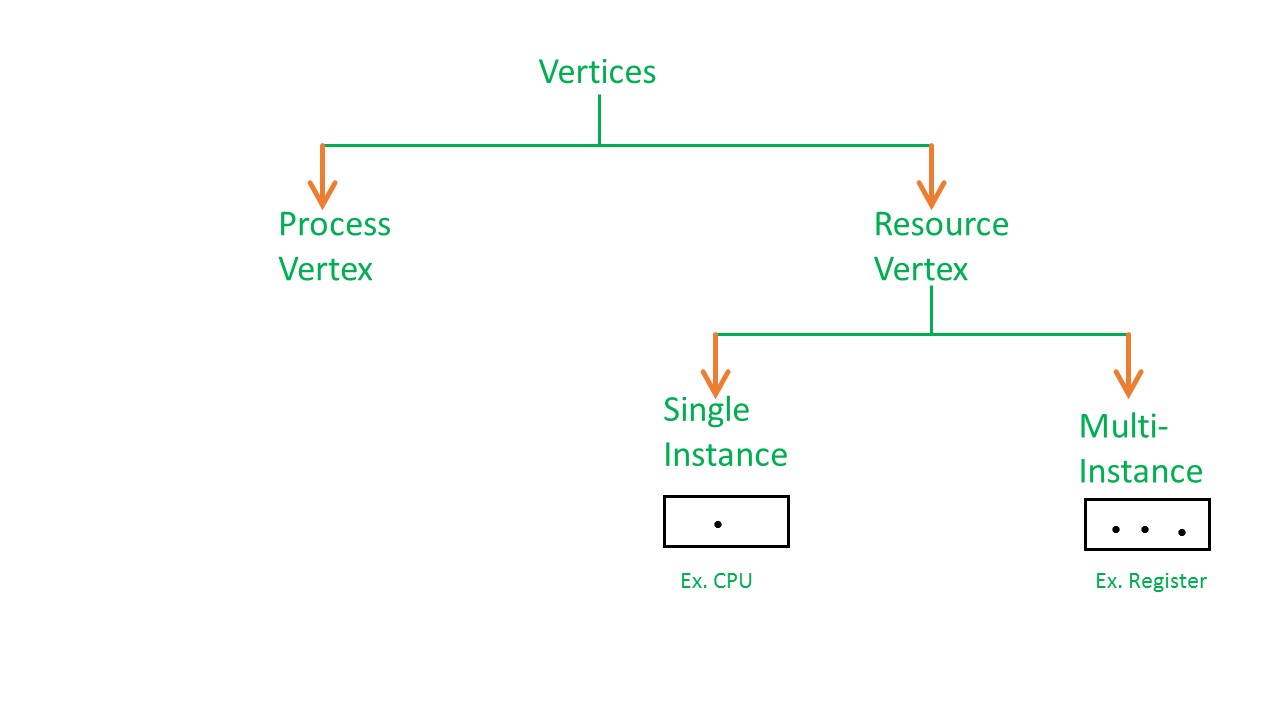
资源分配图是一种用于表示资源分配的图形化工具。我们可以通过资源分配图来判断当前系统是否处在死锁状态。资源分配图由节点(vertices) 和 边(edges) 构成,不同的节点和边拥有不同的含义。
RAG有两种节点:资源节点(resource vertex) 和进程节点(process vertex) ,其中我们用圆圈表示进程节点,用方框表示资源节点。资源节点中点的数量表示资源的数量。
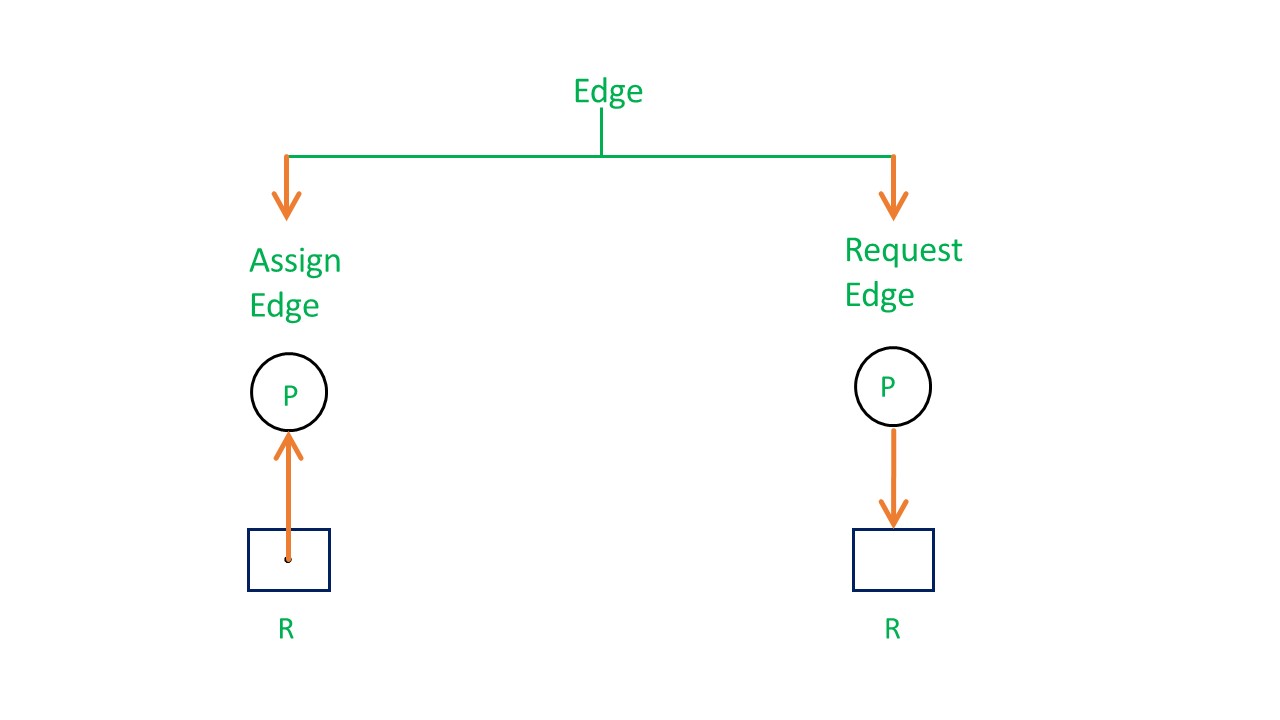
RAG中的边也有两种:申请边(assign edge) 和 分配边(request edge)。申请边表示进程P申请箭头指向的资源,分配边表示当前的资源被进程P所持有。
3.4.2.1 RAG and Deadlock
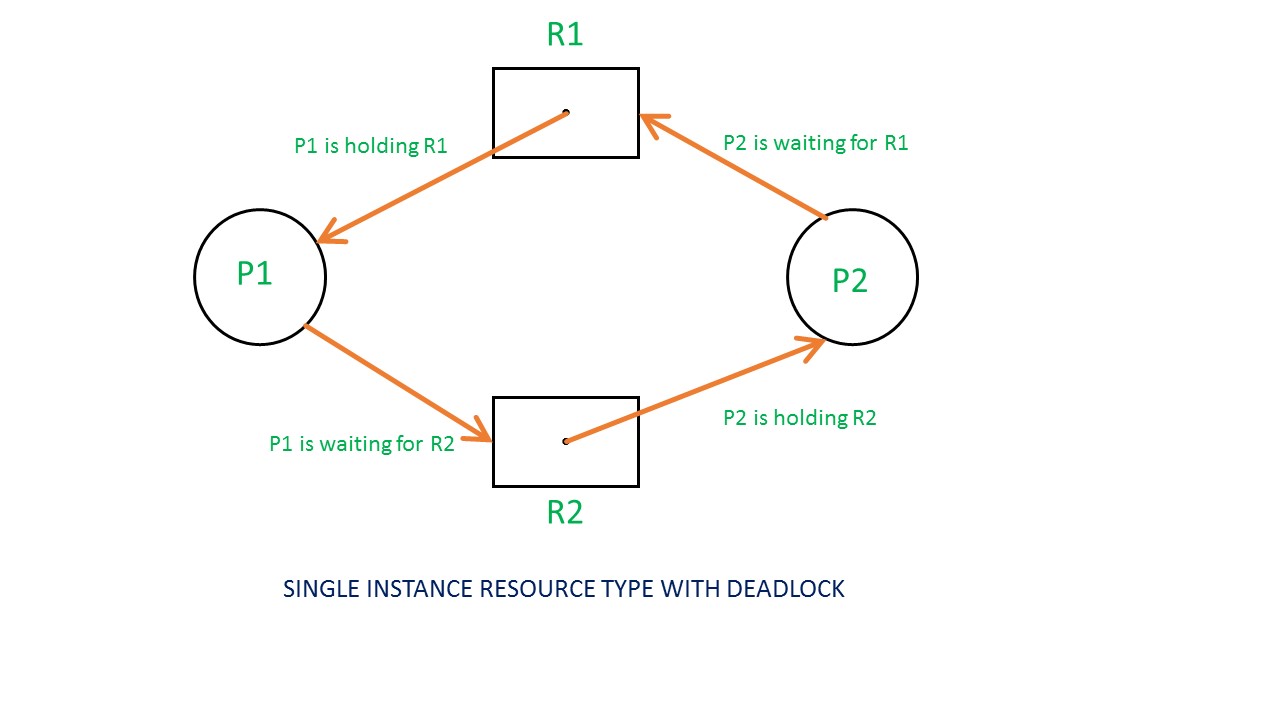
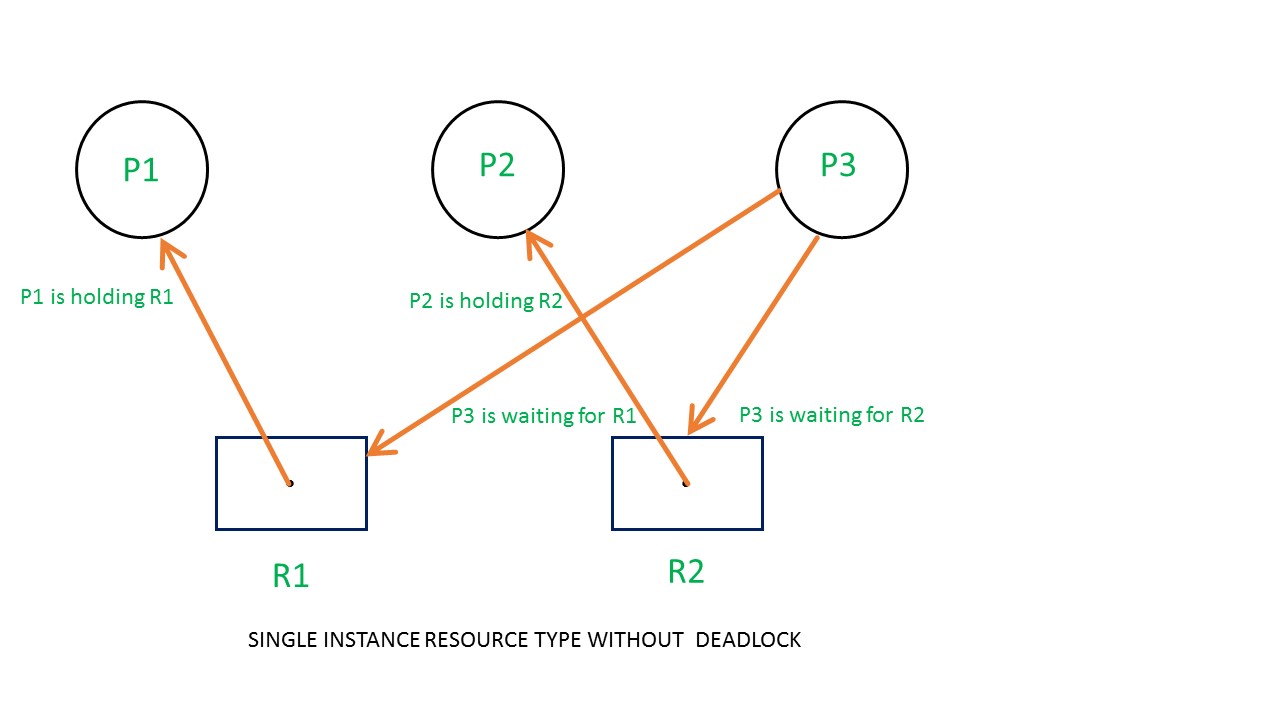
Example 1 (Single instances RAG)
下面两图展示了当资源数为1时RAG的两种情况。第一张图是单资源有死锁的RAG。P1进程和P2进程都渴望获得对方持有的资源,但同时又持有对方想获得的资源,我们称这种情况为环状依赖(circular dependency)。在资源数为1的情况下,如果RAG存在环状依赖就会形成死锁。
下面这张图是另一种资源数为1的RAG。由于不存在环状依赖因此不存在死锁。
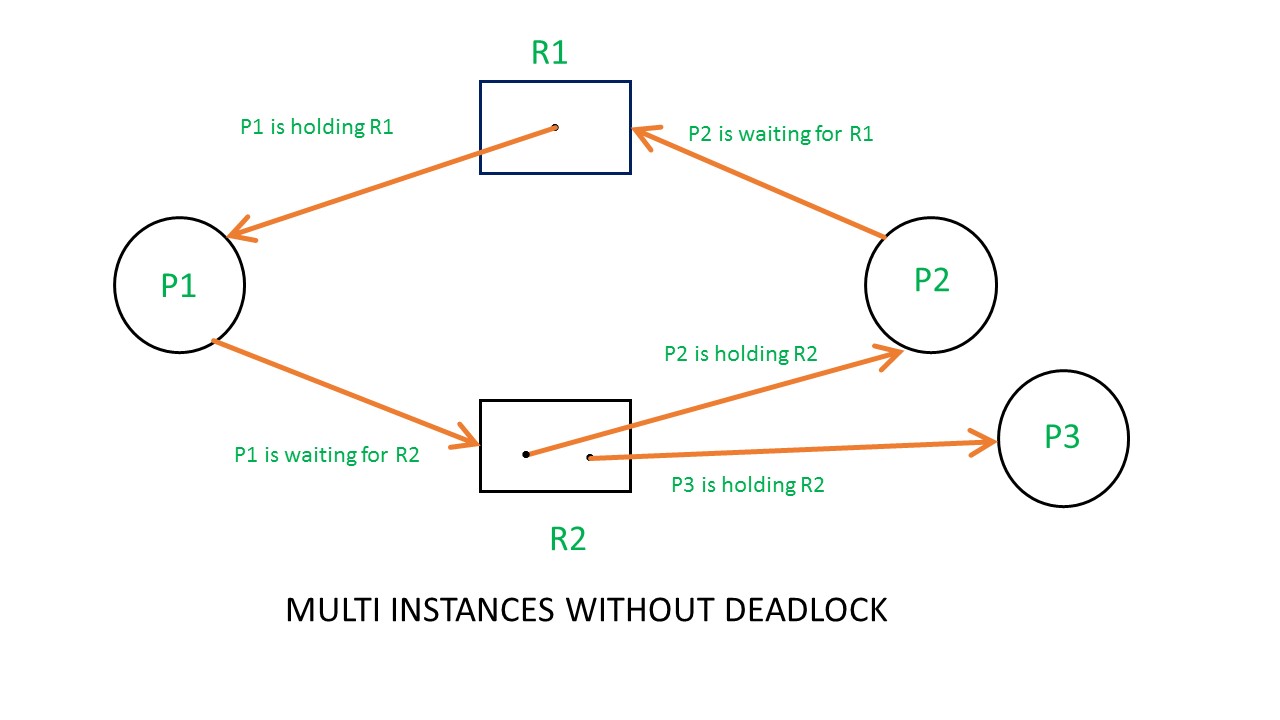
Example 2 (Multi-instances RAG)
当某个资源节点的资源数不止一个时,分析系统的资源分配就会开始变得复杂。下面我们展示了多资源无死锁的RAG,虽然我们可以在RAG中看到环状依赖,但系统不会因此发生死锁。P3并不请求资源,所以P3可以安全地释放资源R2。而P1需要R2,一旦P3释放R2,P1就可以得到R2并释放R1。最后,P2获得P1所释放的R1并释放R2。不会发生死锁。
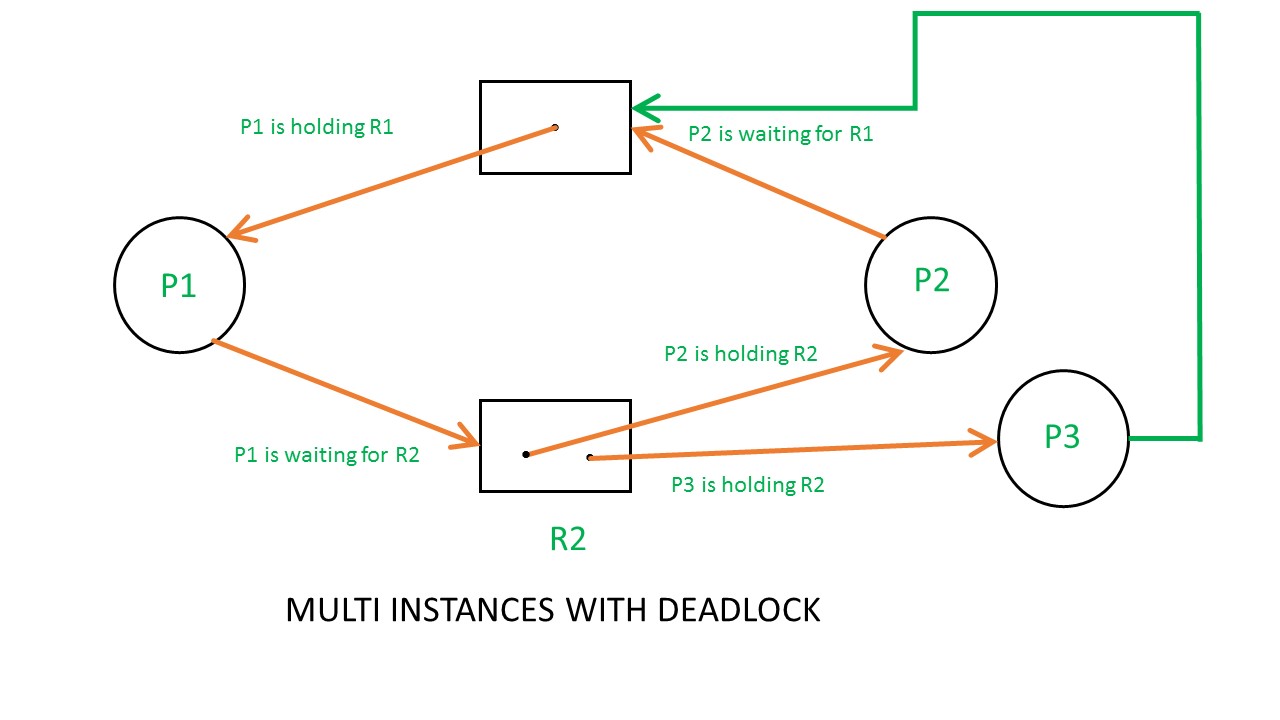
如果我们在上图中加入一个请求边,情况则大有不同,这时RAG会变成多资源有死锁的RAG。我们在下面的请求矩阵和分配矩阵中可以一睹真容。
3.4.2.2 RAG Simplify
化简方法
- 约去分配边:如果一个进程可以顺利结束,则会释放占有的资源,那么我们就可以约去这个进程节点的分配边。
- 约去申请边:如果一个进程可以申请到某类资源,则我们可以约去这个进程节点的申请边。
重要命题
- 如果一个系统的RAG是可完全化简的(所有分配边和申请边都可约),则该状态不是死锁状态。
- 如果一个系统不是死锁状态,则它的RAG可完全化简。
3.4.3 Wait-For Graph (WFG)
3.4.3.1 Cycle Detection in WFG
我们在RAG中检测图中是否存在环状依赖来推测系统中是否存在死锁,这些工作由cycle detection algorithm来完成。假如图中的进程节点和资源节点有
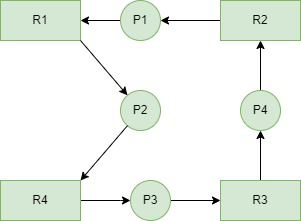
当资源节点的只有单例时,我们可以将RAG化简成wait-for graph。
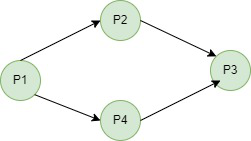
虽然对于人类而言,有些环状依赖一眼就能看出来,好像对RAG的化简没有多大作用。对于机器而言,我们前面看到了,节点的减少对环状依赖的检测速度提升是巨大的。由于WFG的节点更少了,所以WFG中算法检测环状依赖的速度更快,因此WFG被专门用于检测系统中的死锁情况。
3.4.4 General Deadlock Detection Algorithm
为支持系统每种资源类型的多种实例,我们可以用通用死锁检测算法来判断系统内是否存在死锁。
3.4.4.1 Vectors and Matrices
假设我们有从
Resources in Existence Vector:
3.4.4.2 General Deadlock Detection Algorithm
通用死锁检测算法判断死锁的方法和银行家算法一样,都是判断、资源分配、资源回收。因而也被称作扩展的银行家算法,因为其支持多种资源类型和实例,适用于更复杂的系统环境。我们来看看这种算法检测死锁的基本思想:
- 初始化:
- 设置工作向量
- 设置
- 设置工作向量
- 寻找符合条件的进程:
- 找到一个
Finish[i] = False Need[i] ≤ Work
- 找到一个
- 资源分配:
- 如果找到了这样一个进程,则将其资源加到
Finish[i] = True
- 如果找到了这样一个进程,则将其资源加到
- 循环检查:
- 返回步骤2,继续检查,直到无法找到这样的进程。
- 检测结果:
- 如果所有进程的
- 如果有未完成的进程,系统可能处于死锁状态。
- 如果所有进程的
这种支持多重实例的死锁检测算法的时间复杂度将会是
3.4.5 When to Detect?
什么时候该检测死锁呢?每次资源的申请的时候?那就和死锁的避免无异了,代价太沉重了,得换一个。当进程申请资源不到时,其会显然阻塞态,那要不在进程/线程被阻塞时检测?阻塞好像也挺频繁的,感觉也不行。那干脆就周期性的检测一次吧?听上去好像不错。
现在我们的问题就变成了 "how often a detection is reasonable?"。如果死锁经常发生,经常性地检测死锁听上去好像不错。但有的关键系统(critical system)发生死锁后,我们需要立即将其从死锁中恢复出来,定时检测可能满足不了这一需求。
那我们换个思路,从CPU的负载出发。当死锁发生时,许多的进程都阻塞起来了,CPU上运行的进程数将会减少,负载也会下降。当CPU低负荷运行或CPU利用率一时间忽然降低,可能就是死锁发生的信号。在这种情况下设置一个检测点来进行死锁检测是一个好方法。
3.4.6 Recover from a Deadlock
当检测到死锁后,我们需要采取一些措施对死锁进行恢复。虽然我们可以有不同的策略对死锁进行恢复,理想情况下我们想要像一切没有发生过一样结束死锁。但是只要发生死锁,恢复都是需要代价来进行交换的。这些代价可能是数据的丢失、任务完成延时或其他问题。
3.4.6.1 Resource Preemption
资源抢占是指根据优先级或其他标准,操作系统选择部分进程,强制回收其占有的资源,并将这些资源重新分配给其他更需要的进程。在这个过程中,操作系统需要记录被抢占进程所拥有的资源(相当于打“白条”),抢走这些资源并将进程阻塞,等到合适的时候将资源归还给被抢占的进程。
对于资源抢占来说,例如CPU时间片、网络带宽等这类资源可以被抢占,因为操作系统可以轻易地记录并归还这类资源。而打印机、内存这类资源通常不适合被抢占,因为抢占这类资源可能会导致无法恢复的错误或数据损坏。
3.4.6.2 Process Termination
对于结束死锁而言,进行一场对所有引发死锁进程的“屠杀”是一种最简单和高效的方法。而且这种方法十分常见。这种方法虽然易于实现,但可能不能从根本上解决问题。如果导致死锁的环境依然存在,死锁可能会再次发生,此时再一次终止所有相关进程似乎不太合适。
“大屠杀”并非优选,我们想让“处理”变得更优雅一些,该怎么做?我们可以根据优先级、进程的重要性或进程的执行时间等标准,选择并“处理”一个进程以释放资源。当这一切完成后,操作系统将获得这些进程持有的资源。我们可能需要再运行一次检测算法来确保死锁不会再次发生。如果死锁仍然存在,那就再“处理”一个进程。

在“处理”这些进程时,我们需要注意不能误伤旁观者!下面我们例举一些相关的影响因素:优先级、运行时长、剩余执行时间、拥有的资源种类和数量、未来申请的资源信息、进程的种类 (user-interactive 还是 backgrounded) 和进程被选为受害者终止的次数。
3.4.6.3 Roll-Back
回滚是将进程状态回退到进程早些时候保存过的一个状态。要进行回滚,进程必须事先保存过至少一个状态,不然就没有能够回滚的状态。这些保存的状态被称为检查点(checkpoint),相当于进程的存档点。进程可以在需要申请很多资源之前创建一个检查点。
检查点包含了存储映像,其中包括调用栈(call stack)和进程的资源状态。设置检查点时,通常会将其写到磁盘上以便长期保存,防止因系统掉电等意外造成进程终止导致的信息丢失。回滚本质上类似于版本控制,我们使用的版本控制软件如Git和Subversion也是基于相同的原理。
但是很遗憾,回滚也不能完全解决死锁问题。和终止进程一样,回滚可能使进程回到发生死锁的前几步,紧接着又踏上了通往死锁的道路。在系统寻找其他策略之前,可能会尝试多次回滚。
3.4.6.4 Rebooting
我们还有杀伤力更大的方法。就是重启机器。
3.5 Ignore Deadlock
我们在本节课中介绍了从严格到宽松的四种死锁解决方案。现代的操作系统多数情况下不主动处理死锁,采用鸵鸟算法来处理死锁,这样做有以下几个原因:
- 复杂度和开销
- 死锁发生概率不大
- 应用程序级别处理
Windows 和 Linux 等主流操作系统通常不再内核层面主动处理死锁,而是提供死锁检测器供开发者检测和调试。MySQL 数据库系统通常会内置死锁检测机制,可以自动检测并终止死锁进程,恢复系统正常运行。
如果真的发生死锁怎么办?
或者re-boot
第四课 Live-lock
活锁(Livelock) 是指一组进程在试图解决资源争用或其他问题时不断地改变状态但无法取得进展。尽管进程没有完全阻塞(即没有进入死锁状态),但它们也无法完成工作。通常这是由于进程在响应对方的动作时不停地相互让步,却总是错过能够完成任务的时机。
比如两个进程A和B,每次检测到对方正在占用某资源时都会释放自己的资源,让对方先用。结果,两个进程不断重复“试探-释放”的循环,导致没有任何进程能够实际获取到资源进行工作。
这个比喻相当于两个人不断互相礼让,“你先”,“不,你先”,最终谁都没有通过门。尽管他们没有阻塞,但也没有取得实质性的进展。
为了防止活锁,可以通过引入随机延迟、优先级机制或限制重试次数等方法,确保进程能够在适当的时机取得所需资源并完成工作。